在数学中,一个图(Graph)是表示物件与物件之间关系的方法,是图论的基本研究对象.一个图是由顶点(Vertex)与连接这些顶点的边(Edge)组成的.
图论作为数学领域中的一个重要分支已经有数百年的历史了.人们发现了图的许多重要而实用的性质,发明了许多重要的算法,给你一个图(Graph)你可以联想到许多问题: 两个顶点之间是否存在一条链接?如果存在,两个顶点之间最短的连接又是哪一条?….
在生活中,到处都可以发现图论的应用:
- 地图: 在使用地图中,我们经常会想知道”从xx到xx的最短路线”这样的问题,要回答这些问题,就需要把地图抽象成一个
图(Graph),十字路口就是顶点,公路就是边.
- 互联网: 整个互联网其实就是一张
图,它的顶点为网页,边为超链接.而图论可以帮助我们在网络上定位信息.
- 任务调度: 当一些任务拥有优先级限制且需要满足前置条件时,如何在满足条件的情况下用最少的时间完成就需要用到
图论.
- 社交网络: 在使用社交网站时,你就是一个
顶点,你和你的朋友建立的关系则是边.分析这些社交网络的性质也是图论的一个重要应用.
图就是由一组顶点和一组能够将两个顶点相连的边组成的.
基本术语
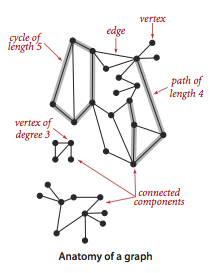
- 相邻: 当两个
顶点通过一条边相连接时,这两个顶点即为相邻的(也可以说这条边依附于这两个顶点).
- 度数: 某个
顶点的度数即为依附于它的边的总数.
- 阶:
图G中的顶点集合V的大小称为G的阶.
- 自环: 一条连接一个
顶点和其自身的边.
平行边: 连接同一对
顶点的两条边称为平行边.桥: 如果去掉一条
边会使整个图变成非连通图,则该边称为桥.路径: 当
顶点v到顶点w是连通时,我们用v->x->y->w为一条v到w的路径,用v->x->y->v表示一条环.
- 子图: 也称作
连通分量,它由一张图的所有边的一个子集组成的图(以及依附的所有顶点).
- 连通图:
连通图是一个整体,而非连通图则包含两个或多个连通分量.
- 稀疏图: 如果一张图中不同的
边的数量在顶点总数V的一个小的常数倍内,那么该图就为稀疏图,否则为稠密图.
- 简单图与多重图: 含有
平行边与自环的图称为多重图,而不含有平行边和自环的图称为简单图.
树
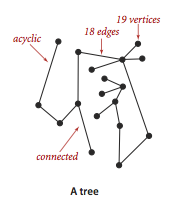
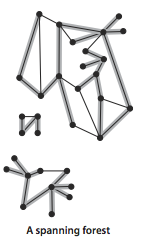
树是一张无环连通图,互不相连的树组成的集合称为森林.连通图的生成树是它的一张子图,它含有图中的所有顶点且是一棵树.图的生成树森林是它的所有连通分量的生成树的集合.
图G只要满足以下性质,那么它就是一棵树:
G有V-1条边且不含有环.
G有V-1条边且是连通的.
G是连通的,但删除任意一条边都会使它不再连通.
G是无环图,但添加任意一条边都会产生一条环.
G中的任意一对顶点之间仅存在一条简单路径(一条没有重复顶点的路径).
二分图

二分图是一种能够将所有顶点分为两部分的图,其中图的每条边所连接的两个顶点都分别属于不同的部分.
设G = (V,E)为一张无向图,如果顶点V可以分割为两个互不相交的子集(U,V),且图中的每条边(x,y)所关联的两个顶点x,y分别属于这两个不同的顶点集合(x in U , y in V),则G为二分图.
也可以将(U,V)当做一张着色图: U中的所有顶点为蓝色,V中的所有顶点为绿色,每条边所关联的两个顶点颜色不同.
无向图
无向图是一种最简单的图模型,它的每条边都没有方向.
图的表示方法
实现一张图的API需要满足以下两个要求:
- 必须为可能在应用中碰到的各种类型的
图预留出足够的空间.
图的实现一定要足够快(因为这是所有处理图的算法的基础结构).
有以下三种数据结构能够用来表示一张图:
- 邻接矩阵: 使用一个
V * V的布尔矩阵.当顶点v和顶点w之间有相连接的边时,将v行w列的元素设为true,否则为false.这种方法不符合第一个条件,当图的顶点非常多时,邻接矩阵所需的空间将会非常大.且它无法表示平行边.
- 边的数组: 使用一个
Edge类,它含有两个int成员变量来表示所依附的顶点.这种方法简单直接但不满足第二个条件(要实现查询邻接点的函数需要检查图中的所有边).
- 邻接表数组: 使用一个
顶点为索引的链表数组,其中的每个元素都是和该顶点相邻的顶点列表(邻接点).这种方法同时满足了两个条件,我们会使用这种方法来实现图的数据结构.
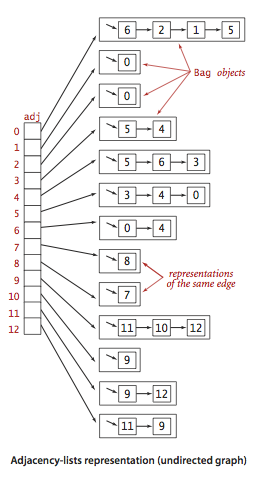
实现
|
|
上面的这个实现拥有以下特点:
- 使用的空间和
V + E成正比.
- 添加一条边所需的时间为常数.
- 遍历顶点
v的所有邻接点所需的时间和v的度数成正比(处理每个邻接点所需的时间为常数).
- 边的插入顺序决定了邻接表中顶点的出现顺序.
- 支持平行边与自环.
- 不支持添加或删除顶点的操作(如果想要支持这些操作需要使用一个
符号表来代替由顶点索引构成的数组).
- 不支持删除边的操作(如果想要支持这个操作需要使用一个
SET来代替Bag来实现邻接表,这种方法也叫邻接集).
每种图实现的性能复杂度如下表:
| 数据结构 | 所需空间 | 添加一条边v - w | 检查w和v是否相邻 | 遍历v的所有邻接点 |
|---|---|---|---|---|
| 边的数组 | E | 1 | E | E |
| 邻接矩阵 | V^2 | 1 | 1 | V |
| 邻接表 | E+V | 1 | degree(V) | degree(V) |
| 邻接集 | E+V | logV | logV | logV+degree(V) |
本文中的所有完整代码可以到我的GitHub中查看.
深度优先搜索
处理图的基本问题: v 到 w是否是相连的?. 深度优先搜索就是用于解决这样问题的,它会沿着图的边寻找和起点连通的所有顶点.

如其名一样,深度优先搜素就是沿着图的深度来遍历顶点,它类似于走迷宫,会沿着一条路径一直走,直到走到尽头时再回退到上一个路口.为了防止迷路,还需要使用工具来标记已走过的路口(在我们的代码实现中使用一个布尔数组来进行标记).
递归实现
使用递归方法来实现深度优先搜索会很简洁,当遇到一个顶点时:
- 将它标记为已访问.
- 递归地访问它的所有没有被访问过的邻接点.
|
|
非递归实现
如果是了解JVM中函数调用的小伙伴们应该知道,函数都会封装成一个个栈帧然后压入虚拟机栈,上述的递归实现其实就是在隐式的使用到了栈,要想实现非递归,我们需要显式使用栈这个数据结构.
|
|
寻找路径
在图的应用中,找出v-w的可达路径也是常见的问题之一.

我们基于深度优先搜索实现寻找路径,并添加一个edgeTo[]整形数组来记录路径.例如,在由边v-w第一次访问任意w时,将edgeTo[w]设为v来记录这条路径(v-w是从起点到w的路径上最后一条已知的边).这样搜索到的路径就是一颗以起点为根的树,edgeTo[]是一颗由父链接表示的树.
|
|
广度优先搜索
对于寻找一条最短路径,深度优先搜索没有什么作为,因为它遍历整个图的顺序和找出最短路径的目标没有任何关系.这种问题就需要用到广度优先搜索.
广度优先搜索是沿着宽度来进行搜索的.例如,要找到s到v的最短路径,从s开始,在所有由一条边就可以到达的顶点中寻找v,如果找不到就继续在与s距离两条边的所有顶点中寻找v,以此类推.
如果说深度优先搜索是一个人在走迷宫,那么广度优先搜索就是一群人一起朝着各个方向去走迷宫.
在广度优先搜索中,我们使用一个队列来保存所有已被标记过但邻接表还未被检查过的顶点.先将起点放入队列,然后重复以下步骤直到队列为空:
- 取出
队列中的下一个顶点并标记.
- 将它相邻的所有未被标记过的
顶点加入队列.
|
|
不管是深度优先搜索还是广度优先搜索,它们都是先将起点存入一个数据结构中,然后重复以下步骤直到数据结构被清空:
- 取其中的下一个
顶点并标记它.
- 将它的所有
相邻而又未被标记的顶点放入数据结构中.
这两种算法的不同之处仅在于从数据结构中获取下一个顶点的规则(对于广度优先搜索来说是最早加入的顶点,对于深度优先搜索来说是最晚加入的顶点).
深度优先搜索的方式是不断寻找离起点更远的顶点,直到碰见死胡同时才返回近处顶点.
广度优先搜索的方式是先覆盖起点附近的顶点,只有当邻接的所有顶点都被访问过之后才继续前进.
深度优先搜素的路径通常长且曲折,广度优先搜索的路径则短而直接.但不管是使用哪种算法,所有与起点连通的顶点和边都会被访问到.
连通分量
深度优先搜索的一个重要应用就是寻找出一幅图中的所有连通分量.

|
|
检测环与双色问题
深度优先搜索的应用远不于此,它还可以用来检测是否有环以及双色问题.
检测环
|
|
检测双色
|
|
符号图
在很多应用中,是使用字符串而非整数来表示顶点的,为了适应这种需求,需要拥有以下性质的输入格式:
- 顶点名是字符串.
- 用指定的分隔符来隔开顶点名
- 每一行都表示一组边的集合,每一条边都连接着这一行的第一个名称表示的顶点和其他名称所表示的顶点.
- 顶点集
V与边集E都是隐式定义的.
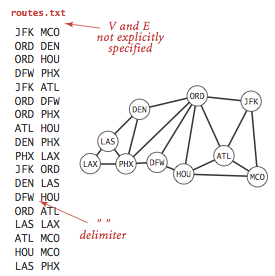
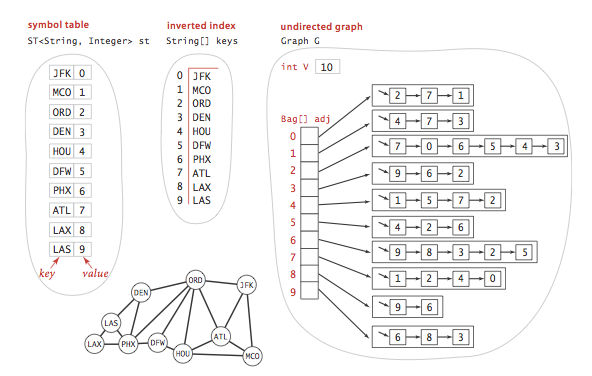
要实现符号图还需要借助以下数据结构:
- 一个
符号表,我这里使用的是TreeMap即红黑树,它的Key为String(顶点名),Value为Integer(顶点索引).
- 一个
字符串数组,它用来与符号表作反向索引,保存每个顶点索引所对应的顶点名.
- 一个
Graph对象,我们使用索引来生成这张图对象.

代码实现
|
|
参考资料
本文作者为SylvanasSun(sylvanassun_xtz@163.com),转载请务必指明原文链接.